Reinforcement Learning
In reinforcement learning an acting agent learns to map observations to actions, in an effort to maximize a reward signal. This course, and the following book are excellent resources for an introduction to reinforcement learning. Note that auditing the course gives you the book for free:
Reinforcement Learning, second edition: An Introduction; Authors Richard S. Sutton, Andrew G. Barto; Publisher MIT Press, 2018
Super Mario Bros
The following GIF is a validation run for one of the better Super Mario World AIs I trained. The Super Mario Bros environment is from Farama's gymnasium (fork of OpenAI Gym). I used the recurrent PPO from Stable Baselines 3 Contrib, which uses an LSTM along with the PPO Deep Reinforcement Learning (DRL) algorithm, and a CNN feature extractor. It was trained for 1,000,000 timesteps with 32 parallel environments. It learns from an RGB pixel array, so this is a computer vision control task.
I started with the default Atari hyperparameters, modified them some to shrink it down enough to fit on my GPU memory, and tuned the parameters a bit from there. The long train time discouraged me from persuing the tuning further as I was running this locally on a single RTX3090 GPU, which took around 8 hours for one training run which consisted of one million timesteps. I found that running more environments simultaneously was far more efficient since PPO itself was the compute bottleneck. I'm planning on revisiting this after having resolved some issues with my GPU. Aside from tuning the parameters, I converted the action-space from discrete to vector-valued, so the agent can reason about directions. I found an issue with jumping over tall pipes, since the a-button must be help down consistently for many frames in order to achieve a tall jump (letting go even for a single frame will end the jump, and PPO is a stochastic policy so it was nearly impossible to jump over the taller pipes). To address this I changed the jump dimension of the action-space to be a plan for the number of frames to hold the jump button, which enabled the agent to get past the taller pipes with ease. Overall I feel that converting actions to be vectors with planned jump height mimics human player reasoning better than having the actions be discrete combinations of buttons. Overall I was able to decrease the train time to get to the second level by roughly a factor of 1/10, from 10^6 timesteps to 10^4 timesteps, though this was not consistent. More work is necessary to fully root this out.
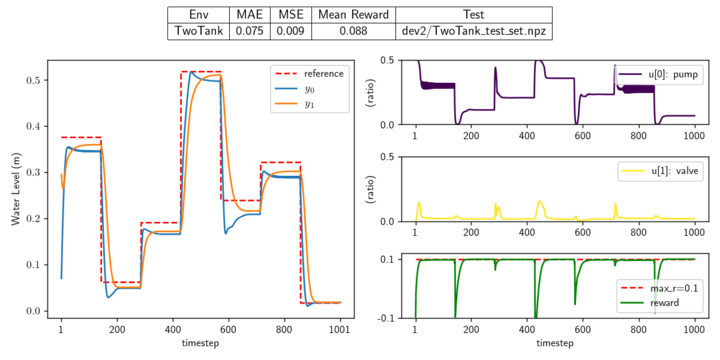
For the remaining control problems I compared 7 DRL algorithms from Stable Baselines: A2C, DDPG, PPO, SAC, TD3, TQC, and TRPO. Each algorithm was tuned with RL Zoo3's optuna-based tuning algorithm, and given 128 configurations, each with 100,000 timesteps. Only the test runs for the best-in-development algorithms, configurations, and weights are shown. TQC was uniformly one of the highest performing algorithms, and was the best in many cases. TD3 and SAC were also found to generally perform well in these problems.
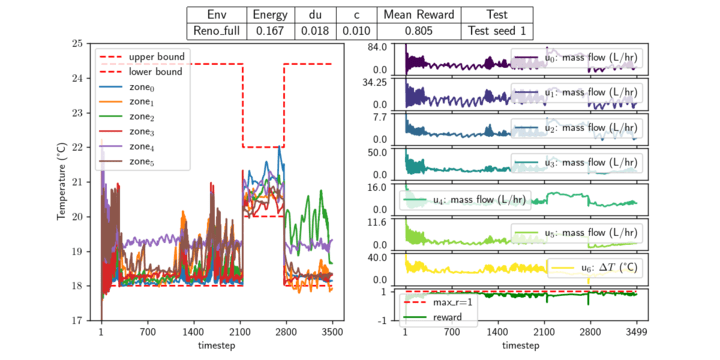
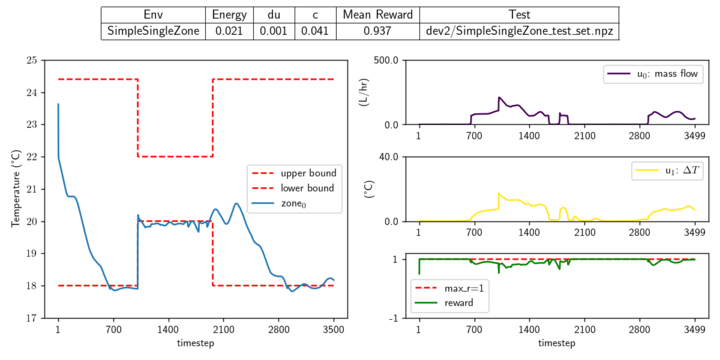
The systems in the section are building simulators from the Neuromancer PSL module which I have made open-source contributions to. The task is constrained energy management, controlling the boiler temperature and airflow to each zone. The dashed red lines represent the thermal constraint band, and the individual zone temperatures are shown between them. The right-hand side of each figure shows the corresponding actions (temperature and airflow).
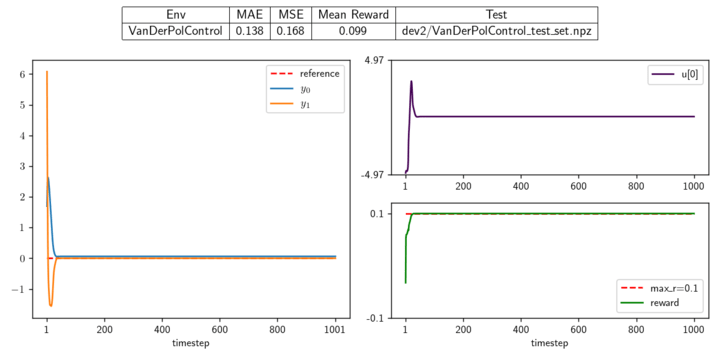
System: Reno_full, Controller: TQC System: Single Zone, Controller: TD3 System: TwoTank, Controller: TQC System: Van der Pol, Controller: TQC
Van der Pol Oscillator: defined by a system of differential equations:
dx₀/dt = x₁,
dx₁/dt = (1 - x₀²) ⋅ x₁ - x₀ + u
Where the state is defined as x=(x₀, x₁), and the action u is a number between -5 and 5. The goal is to set the state to 0.
The remaining five control systems are Farama Gymnasium environments. The following three were started from pre-optimized default parameters from RL Zoo 3. System: BipedalWalker-v3, Controller: TQC System: LunarLanderContinuous-v2, Controller: TQC System: MountainCarContinuous-v0, Controller: TQC The remaining two systems were modified from the base Farama gymnasium environments to have continuous action space. Acrobot (left) was also modified to not terminate after hitting the ceiling, which changes the goal to remain above the ceiling as much as possible, rather than to touch it as soon as possible. This significantly changes the optimal control task. Due to these differences, the default parameters for Lunar Lander were used to seed the search. System: Acrobot Continuous, Controller: TQC System: Pendulum Continuous, Controller: SAC The link provided shows the code to a maze-running AI I wrote just before starting my MCS, using a modified Q-learning algorithm which decreases the probability of re-visiting states recently visited. This modification effectively prevents it from getting stuck at dead-ends, allowing it to complete randomized mazes (assuming the given randomized maze is possible).
Building Control
Other PSL Systems
Gymnasium Environments with Defaults



Maze Runner
Supervised Deep Learning
Sick Plant Identification
From the D4-Computer Vision Kaggle Competition I took part in, performing all tuning on a single 3090RTX GPU. I predicted whether a plant is sick to 96.5% accuracy with a single submission. Currently Gretta Buttelmann holds first place in the leaderboard with 96.7% accuracy, with four submissions. I do not plan to submit more entries since there is no prize for this competition, and I feel I've already gotten what I wanted out of it. The architecture I used was a CNN I wrote from scratch, which uses summary-statistics pooling as a first layer which is cached to files, effectively reducing the size of the data by a factor of 5/(60*40)=0.002, and significantly speeding up training. It uses skip connections and a number of regularization techniques. I augmented the image data with rotations, since if and only if a leaf is sick, then any rotations of the leaf will also be sick. I will probably open-source this soon, so keep an eye on my GitHub if you're interested.

Original image of a sick leaf.

The columns represent each channel of the output of the summary-statistic pooling layer. From left to right, this visualizes the: mean, median, minimum, maximum, and standard deviation of each color of 40x60 regions of the original image. Each row is a different random rotation of the leaf, constrained by increasing maximum rotation angles.
Load Forecasting
Some graphics produced in my master's project, which was grant-funded and part of my Research Assistantship at WWU. The task was time sequence load forecasting in smart buildings, and involved several transfer learning experiments. I compared several deep learning architectures including 2 transformer models, one of which I wrote using the MultiheadAttention module from Pytorch, the other being the Autoformer from HuggingFace. In addition to the transformer, models I tried various MLP architectures with skip connections and batch/layer normalization, a convolutional neural network I implemented in Pytorch which was inspired by ResNet, Pytorch's LSTM class (this actually ended up generalizing better than the others in small data scenarios, though it didn't perform the best in development), and various hybrid ensemble models. I simulated all data in EnergyPlus (with the expert help of Sen Huang) of which I did some work in modifying the actuators and outputs of the simulation via the configuration files, and we utilized 6 different climate/building combos, exploring transfer learning between climates. This was a collaboration with the EED of PNNL. I did most of the coding, but I had plenty of guidance from my advisor, and the domain expert collaborators.
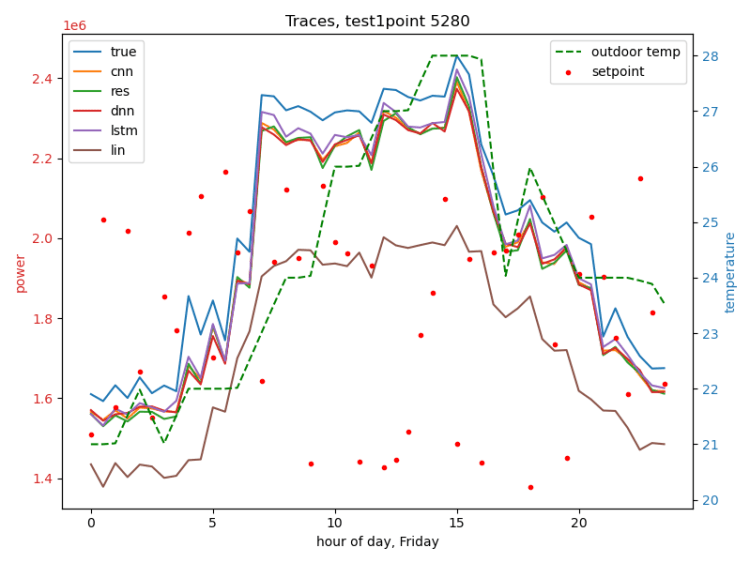
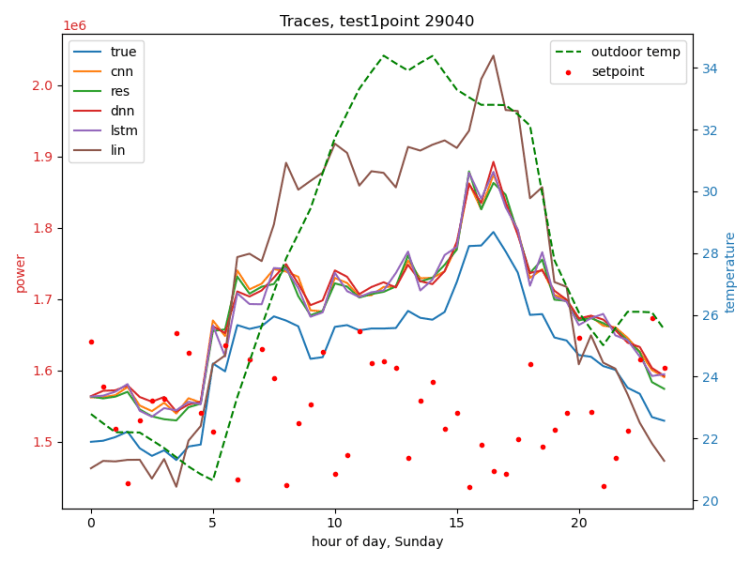
The following figures are traces of several dev-runs of the best model from the large data scenario, which was an MLP. Note that in this phase we were re-using our limited climate data, so we see multiple traces with the same weather.
Same day, same weather, different cooling setpoints:
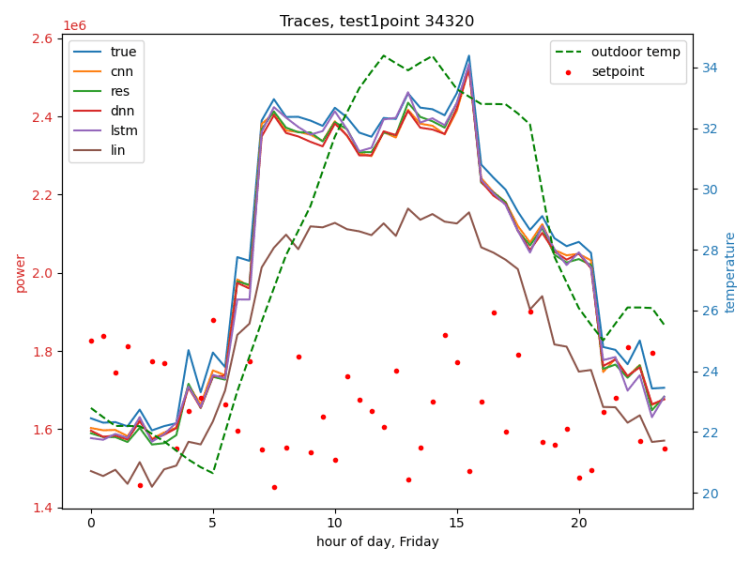
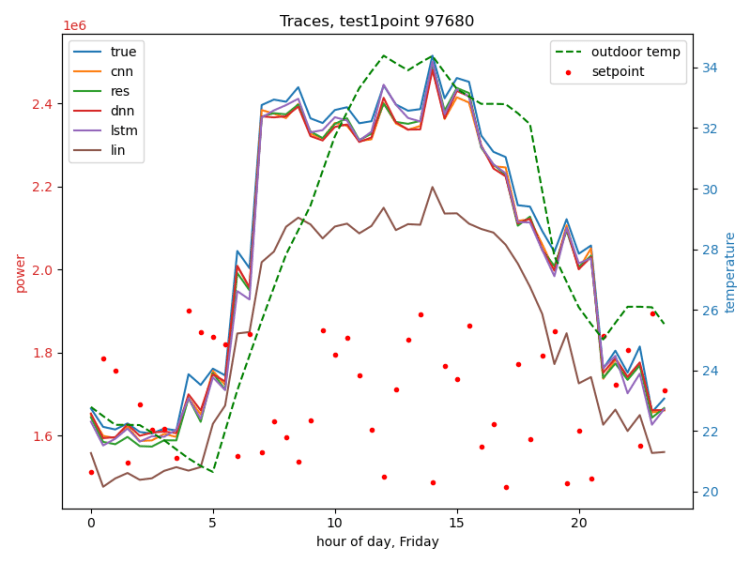
Different weather (left), different day (Sunday) (right):
Climate CNN
I implemented a day-of-the-year predictor using a CNN I wrote in pytorch using built-in modules: https://github.com/Seth1Briney/climate-cnn as part of a deep learning course CSCI581 at WWU. The model predicted the day of the year within 1.4 days on the dev set, and achieved the class record on test, though I didn’t get the specific test metric value. This task is very similar to computer vision, as it uses a global grid of temperature values. My innovation in this project was performing summary-statistics pooling (using mean, median, min, max, std) rather than just max pooling, and performing this as a preprocessing step, saving the output of the first pooling layer to a file for subsequent use (automatically saved to /tmp on each compute node the first time the specific pooling dimensions were run on the given node, and subsequently loaded rather than re-computed). This effectively reduced data dimensionality by a factor of 5/64 which significantly sped up training/tuning.